Serverless
Event Sourcing with AWS Lambda
Overview
This article will explore one possible way to implement the event sourcing pattern in AWS using AWS services. Event sourcing is a pattern that involves saving every state change to your application allowing you to rebuild the application state from scratch via event playback.
When to Use
Event sourcing adds extra complexity to your application and is overkill for many use cases but can be invaluable in the right circumstances. The following are some instances of when you would want to implement the event sourcing pattern.
- When you need an audit log of every event in the system or micro service as opposed to only the current state of the system.
- When you need to be able to replay events after code bug fixes to fix data.
- When you need to be able to reverse events.
- When you want to use the Event Log for debugging.
- When it’s valuable to expose the Event Log to support personnel to fix account specific issues by knowing exactly how the account got into a compromised state.
- When you want to create test environments from the event log. Having the event log can allow you to create environments based on the state of the system at different points in time by replaying only a subset of events.
Event Sourcing Deep Dive
Event sourcing stores every state change to the application in an event object. These event objects are stored in the sequence they were applied for the lifetime of the application.
A core principle of event sourcing is that all changes to domain objects are done as a result of an event. This principle allows us to do a number of useful operations:
- Complete Rebuild: We can start from a clean slate and completely rebuild the application state from events in the event log.
- Event Replay: We replay events in the system with updated application logic to correct incorrect processing of events. Useful for fixing bugs in code and then doing a replay to correct the data.
- Event Reversal: If events are stored as diffs or have reversal information it is possible to reverse specific events without having to do a replay from a clean application state.
Application State Storage
To calculate the recent application state with Event Sourcing we would start from a blank slate and apply all the events to reach the current state. Since most applications commonly request the current application state it is common to store the current application state as well for fast retrieval. If lost or corrupted, the current application state can always be derived from the event log.
Event Reversal
If events are captured as diffs then reversing the event is as simple as undoing the diff. In most cases events will have just the final value, not the diff (Account Balance = $100 vs Account Balance += $20). In this case reversing the event with only the information in the final event is not possible since we do not have sufficient information.
If the event only contains the final value, then it would also need to store information on how to reverse the event.
If storing the reverse information is not viable, then reversing can always be done by playing the event log up to the previous event, effectively reversing the current event.
Interacting with External Systems
External Updates
External systems that are not designed for event sourcing can behave in unintended ways when receiving duplicate update messages during replays. This can be handled by wrapping interactions with external systems in a gateway. The gateway would incorporate logic about the external system and not forward events during replays.
External Queries
The main challenge with external queries is when doing Event Replays. If for any event you need to query an external system that does not support time based queries then the external data will be wrong. You will get the current state of the external data, not the state when the original event was processed.
One option is to log the response of all external queries. During event replays this will allow you to have your gateway to the external system use the logged value to accurately represent the interaction.
Handling Code Changes
There are two main types of code changes that can affect reprocessing of events:
- New features.
- Bug fixes.
New Features
When doing events replays with new features you will want to disable external gateways. This prevents external systems from being updated for features that did not exist at the time the event was generated.
Bug Fixes
In the case of bug fixes we will deploy the code fix and reprocess the events. For events that don’t have any external interactions, this is straightforward and one of the main benefits of event sourcing. After the events are reprocessed the data will be corrected.
With external systems, the gateway needs to know if it can just send the event processed by the fixed code or if there is a diff that needs to be computed before the external system is called. The diff is necessary to reverse the original buggy event that had previously went out to the external system.
Any time sensitive logic, such as do one thing before a certain date and a different thing after the date, will need to be included in the domain model of the event. Time sensitive logic can get messy and is best avoided.
AWS Event Sourcing Design
The following design leverages a number of AWS services:
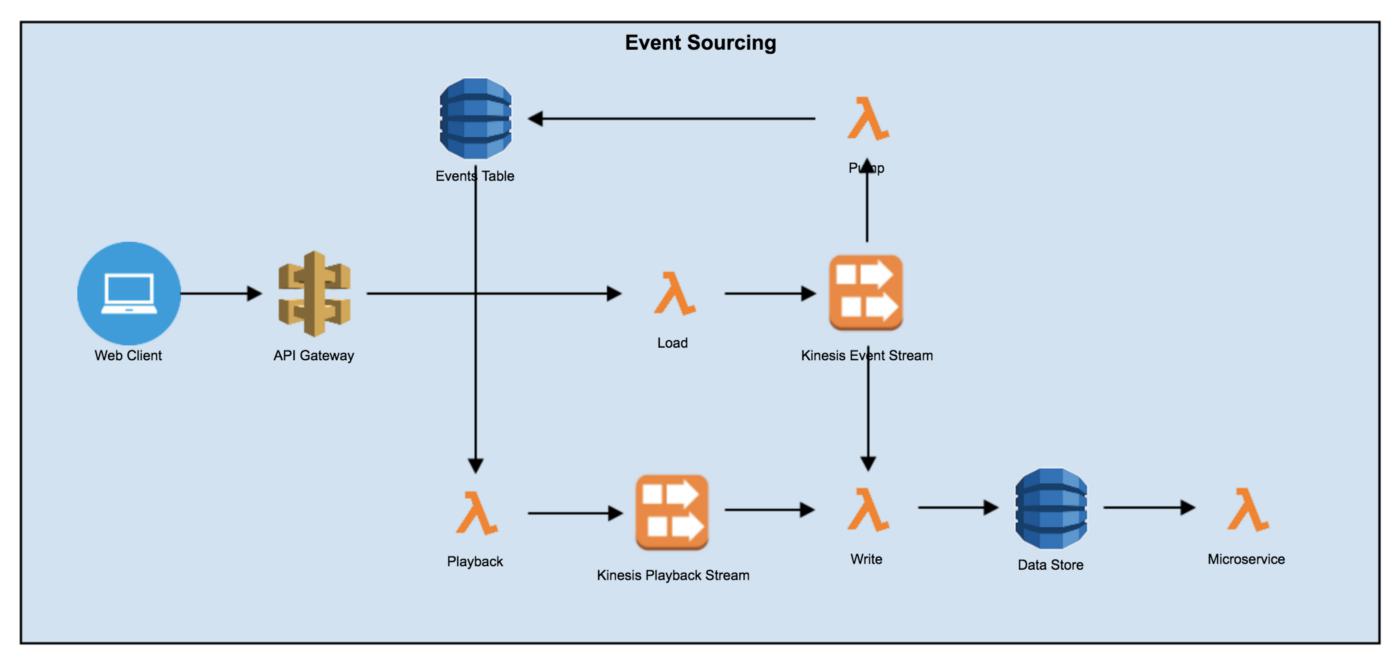
API Gateway
API Gateway is leveraged to receive incoming requests on a web facing url. The API Gateway Method is then configured to forward those requests to an AWS Lambda that acts a loader.
AWS Lambda
Lambdas are leveraged for the following purposes:
Load Lambda: used to load incoming requests from the API Gateway into the Kinesis Event Stream.
Pump Lambda: receives events from the incoming stream and puts them in the Event Store DB.
Write Lambda: receives events from the stream and stores only the latest state in the Data Store DB. Any business logic can be applied here before writing to the DB just like in a regular application.
Playback Lambda: can be triggered manually to read all or a subset of events from the Events Table and send them to the Kinesis Playback Stream. The reason this does not write directly to the Data Store is so you can later attach additional subscribers to the Kinesis Playback stream as your application needs evolve.
Microservice Lambda: this Lambda will contain your application’s business logic and process the incoming event.
DynamoDB
DynamoDB is used to store the events. We have two tables per service.
Events Table: stores every single event that is submitted to the system. This is the immutable system of record for the application.
Data Store: stores the latest state for quick access by the application. This is not the system of record and can be wiped and rebuilt from the Event Table when necessary.