

DevOps
Building a Secure Kubernetes Cluster With a Basic CI/CD Pipeline on AWS
Kuber-what-es?
Kubernetes (pronounced “koo-burr-NET-eez”) is an open-source platform to automate deploying, scaling, and operating application containers. The cool kids often refer to it by the (IOHO) not very good abbreviation “k8s”. Kubernetes’ job is to make the most efficient use of your infrastructure whilst ensuring that your containerised workloads are available and can scale as needed. Some businesses have reported being able to reduce their cloud infrastructure costs by between 50% and 70% compared to running on traditional VM based architecture.
Contain(erise) Your Success
Kubernetes is a massive success story for the Cloud Native Computing Foundation and the open-source community behind it. First announced in mid-2014 as a small project lead by a team of Google engineers, it has grown to be the de facto container orchestration platform and a commodity across the public cloud ecosystem. Microsoft, Google, Amazon and IBM all have a managed Kubernetes offering of some form. In terms of contributors and velocity, Kubernetes is second only in open-source projects to the Linux Kernel. It’s being used at scale for many cool workloads, from powering Pokemon Go to ensuring HBO GO subscribers can smoothly stream Game of Thrones season 7.
Continuous Kubernetes
As users and engineers of modern web applications, we expect them to be available 24 hours a day, 7 days a week, and to be able to deploy new versions of them many times a day. Kubernetes in itself is not enough to achieve this goal. It ensures our containerised applications run when and where we want and can find the tools and resources they require. To fully empower our engineers, however, we need to build a CI/CD pipeline around Kubernetes.
GitOps is a term that has been coined by Weaveworks to describe using Git as the declarative source of truth for the Kubernetes cluster state. Git becomes our means of tracking system state, and we use constructs within git such as pull requests as a means for merging the state held in git with the state of cloud infrastructure. In a nutshell, approved pull requests result in live changes being made to production. This is a really powerful approach since a proven source code workflow can be applied to manage infrastructure — grasping it fully can rid us of old-school bureaucratic change control processes that are complicated, take too long, and lack accountability. The changes enacted on your infrastructure are always 100% visible, traceable, and accountable. The history is stored perpetually in the git repository, and rolling back to any point in history is a piece of cake.
Why Should I Use Kubernetes?
Containers are already a huge success story in cloud computing. Despite the relatively short period of time they’ve been in our toolbox, they have become a staple of modern cloud computing and are leveraged by many household name apps. However, the burden of orchestrating, managing, and maintaining containerised systems can be huge — that’s where Kubernetes comes in. Kubernetes takes all the great strengths behind containerisation and provides a platform for deploying and managing them with greater ease.
Kubernetes is an enabler for DevOps; it helps implement key DevOps practices and paves the way for organisations to implement DevOps. Wherever you install it, be it on your laptop, a cloud provider, or an on-premise data centre, it provides automated deployments of your containerised applications with fully consistent environments. With Kubernetes, gone are the days of building and successfully testing locally, only to find your application behaves differently in test or production environments!
YATR? (Yet Another Tutorial, Really?)
There are plenty of Kubernetes tutorials out there, so why write another one? Good question! In building Kubernetes clusters for our own fun and for clients, we’ve not come across a tutorial that brings together all the pieces needed to setup a cluster on AWS that could be made production ready. The documentation is mostly there, but it’s a treasure hunt to track it down and work out how to make it work in each particular situation. This makes it particularly challenging for anyone embarking on their first Kubernetes pilot or making the step up from a local minikube cluster.
The aim of this tutorial is to close off this gap and step through the setup of Kubernetes cluster that:
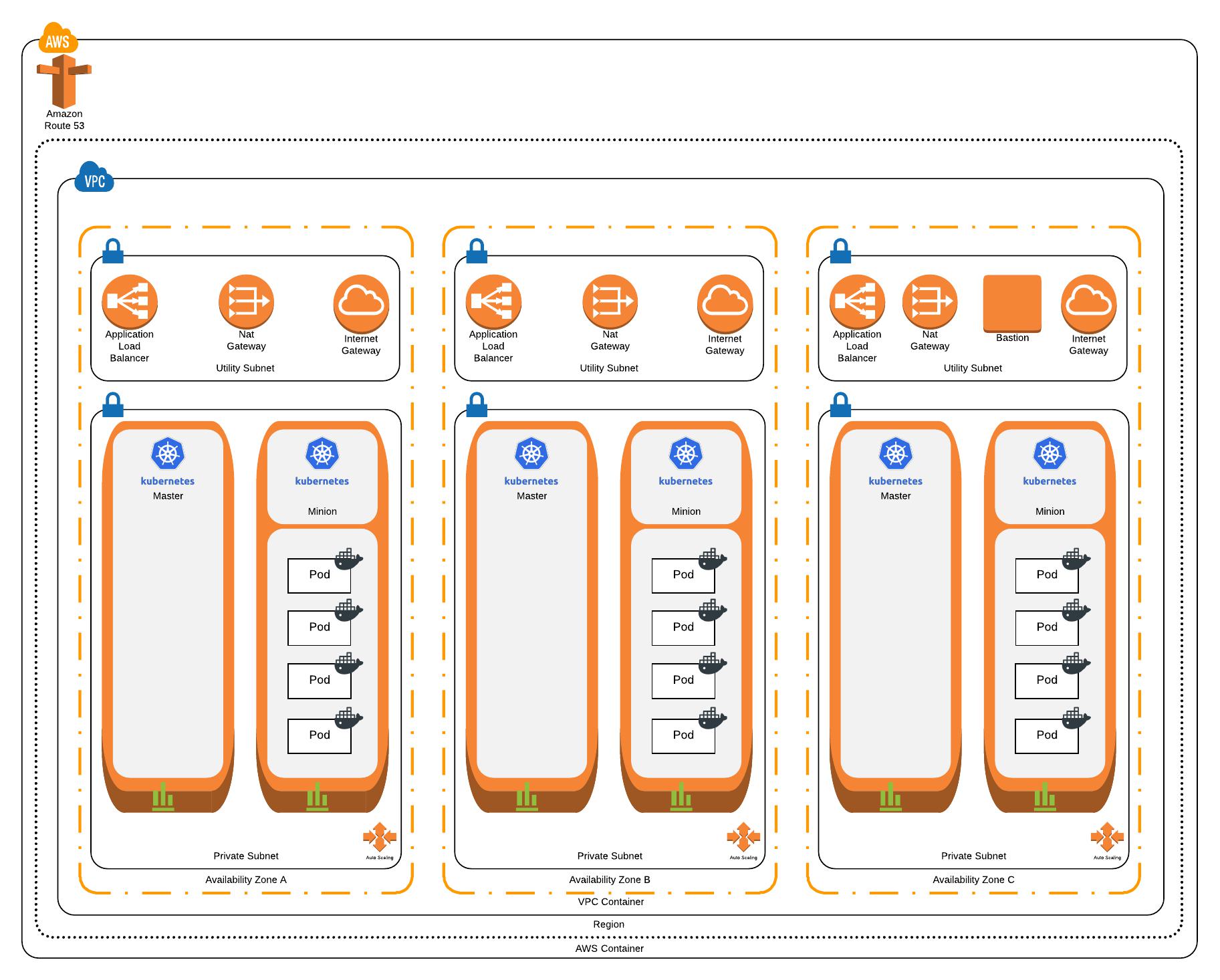
- Is highly available: We want to ensure that our environments can deal with failure and that our containerised applications will carry on running if some of our nodes fail or an AWS Availability Zone experiences an outage. To achieve this, we’ll run Kubernetes masters and nodes across 3 AWS Availability Zones.
- Enforces the “principle of least privilege”: By default all pods should run in a restrictive security context; they should not have the ability to make changes to the Kubernetes cluster or the underlying AWS environment. Any pod that needs to make changes to the Kubernetes cluster should use a named service account with the appropriate role and policies attached. If a pod needs to make calls to the AWS API, the calls should be brokered to ensure that pod has sufficient authorisation to make them and use only temporary IAM credentials. We’ll achieve this by using Kubernetes Role-based Access Control (RBAC) to ensure that by default pods run with no ability to change the cluster configuration. Where specific cluster services need permissions, we will create a specific service account and bind it to a required permission scope (i.e. cluster wide or in just one namespace) and grant the required permissions to that service account. Access to the AWS API will be brokered through kube2iam; all traffic from pods destined for the AWS API will be redirected to kube2iam. Based on annotations in the pod configurations, kube2iam will make a call to the AWS API to retrieve temporary credentials matching the specified role in the annotation and return these to the caller. All other AWS API calls will be proxied through kube2iam to ensure the principle of least privilege is enforced and policy cannot be bypassed.
- Integrates with Route53 and Classic Load Balancers: When we deploy an application, we want the ability to declare in the configuration how it is made available to the world and where it can be found, and have this automated for us. Kubernetes will automatically provision a Classic Load Balancer to an application and external-dns allows us to assign it a friendly Fully Qualified Domain Name (FQDN), all through Infrastructure as Code.
- Has a basic CI/CD pipeline wrapped around it: We want to automate the way in which we make changes to the cluster, and to how we deploy / update applications. The configuration files specifying our cluster configuration will be committed to a Git repository and the CI/CD pipeline will apply them to the cluster. To achieve this, we’ll use Travis-CI to apply the configuration that gets committed in our master branch to the Kubernetes cluster. This is a first step in the direction of GitOps, however it doesn’t give us a full GitOps capability.
At the end of the tutorial, we’ll end up with a Kubernetes cluster that looks like this:
Before you get started
We assume you already have some familiarity with Kubernetes. If you are brand new to Kubernetes, it is recommended you review the Kubernetes Basics tutorial and get yourself familiar with its key concepts.
To build our cluster, we need to make sure we have the following tools installed:
- kubectl
kubectl (Kubernetes Control) is a command line tool for interacting with a Kubernetes cluster, either running locally on your machine (using minikube) or in the cloud. - kops
The Kubernetes Operations (kops) project provides tooling for building and operating Kubernetes clusters in the cloud. It currently supports Google Cloud & AWS (with other providers in beta). We’ll be using kops to create and manage our cluster in this tutorial. - Terraform
Terraform is an Infrastructure as Code (IAC) tool which allows users to define infrastructure in a high-level configuration language which can then be used to build infrastructure in a service provider such as AWS or Google Cloud Platform. We’ll be using Terraform to create our prerequisites for kops and to modify the IAM policies created by kops. - AWS CLI
AWS CLI is a command line tool for interacting with AWS. This is required by kops & Terraform to perform operations on AWS.
Installation instructions can be found at the links provided.
This tutorial was created using Kubernetes v1.8 and kops v1.8.1.
We’re running Mac OS X with Homebrew, so all we need to do is run the following commands to get these installed:
$ brew update $ brew install kubectl $ brew install kops $ brew install python3 $ easy_install pip $ pip install awscli — upgrade — user $ export PATH=~/.local/bin:$PATH $ brew install terraform
Create the Cluster
Step 1: Clone our repository
$ git clone https://github.com/slalom-lond...
Step 2: Setup a FQDN that will be used for the cluster in Route53
The Kubernetes cluster that we will setup will use a FQDN hosted in Route53 to expose service endpoints and the API control plane. You could register a new FQDN or transfer an existing FQDN. AWS has a full step through for each of these options:
Step 3: Create the prerequisites needed for kops
For kops to build the cluster, it needs an S3 store to hold the cluster configuration and an IAM user account that has the following policies attached to it:
AmazonEC2FullAccess AmazonRoute53FullAccess AmazonS3FullAccess IAMFullAccess AmazonVPCFullAccess
prereqs/kops_pre_reqs.tf will create this for you. It will also create an S3 bucket that will be used as a remote store for our Terraform state. This allows multiple users to work with one set of Infrastructure as Code without causing conflicts. You will need to update the file to replace {my_bucket_name} and {my_tf_bucket_name} with your chosen bucket name.
Then run the following commands:
$ cd prereqs $ terraform init $ terraform plan $ terraform apply
If you log into your AWS account, you will now see a newly created kopsIAM user, an S3 bucket for the kops state store, and another S3 bucket for the Terraform state store
Step 4: Use kops to stand-up the cluster
In the previous step, we created an IAM account for kops. Now we need to setup our AWS CLI client to use that account. We can grab the kops IAM ID and secret key from the file Terraform uses to store the state of what it has created in the previous step. Open terraform.tfstate in your text editor and look for the section similar to the below:
"resources": {
"aws_iam_access_key.kops": {
"type": "aws_iam_access_key",
"depends_on": [
"aws_iam_user.kops"
],
"primary": {
"id": "{iam_id}",
"attributes": {
"id": "{iam_id}",
"secret": "{aws_secret_key}",
"ses_smtp_password": "{ses_smtp_password}",
"status": "Active",
"user": "kops"
},
"meta": {},
"tainted": false
},
"deposed": [],
"provider": ""
}Make a note of value in the {iam_id} and {aws_secret_key} fields, and run the following command:
$ aws configure --profile kops
AWS Access Key ID [None]: <strong>{iam_id}</strong>
AWS Secret Access Key [None]: <strong>{aws_secret_key}</strong>
Default region name [None]: <strong><em>{your_chosen_aws_region}
</em></strong>Default output format [None]: <strong><em>text</em></strong>Next we need to set a couple of environmental variables so that kops knows which AWS IAM account to use and where it should put its state store:
$ export AWS_PROFILE=kops
$ export KOPS_STATE_STORE=s3://{my_bucket_name}Now for the main event – let’s use kops to build our cluster. Run the following command, substituting your AWS region, your DNS zone and your chosen cluster name:
$ kops create cluster --cloud aws \
--bastion \
--node-count 3 \
--node-size t2.medium \
--master-size t2.medium \
--zones {your_chosen_aws_region}a,{your_chosen_aws_region}b,{your_chosen_aws_region}c \
--master-zones {your_chosen_aws_region}a,{your_chosen_aws_region}b,{your_chosen_aws_region}c \
--dns-zone {your_dns_zone} \
--topology private \
--networking calico \
--authorization RBAC \
--name {your_cluster_name} \
--out=k8s \
--target=terraform --yes
This command tells kops that we want to build a cluster that:
- Will use AWS
- Has a master node of size t2.medium in each of the specified availability zones
- Has 3 worker nodes of size t2.medium. kops will spread the worker nodes evenly across each of the availability zones
- Uses a private network topology, meaning that the all the nodes have private IP addresses and are not directly accessible from the public Internet
- Uses Calico as a Container Network Interface replacing kubenet as a result of the requirements of the private network topology
- Uses RBAC for Kubernetes access permissions
- Is described in a Terraform configuration file to be written to the directory specified by --out
kops generates a set of Terraform configuration files in a newly created k8sdirectory that can be applied to create the cluster. Before we build our cluster, we want to add a configuration file to tell Terraform to keep its state store on the S3 bucket that we just created.
$ cd k8s $ terraform init $ terraform plan $ terraform apply
It will take between 10 and 15 minutes for your cluster to become available. You can check the status of the cluster by running the following command:
$ kops validate cluster
When the cluster is finished building, you should see an output like this:
Using cluster from kubectl context: cluster.zigzag-london.com Validating cluster cluster.zigzag-london.com INSTANCE GROUPS NAME ROLE MACHINETYPE MIN MAX SUBNETS bastions Bastion t2.micro 1 1 utility-eu-west-1a,utility-eu-west-1b,utility-eu-west-1c master-eu-west-1a Master t2.medium 1 1 eu-west-1a master-eu-west-1b Master t2.medium 1 1 eu-west-1b master-eu-west-1c Master t2.medium 1 1 eu-west-1c nodes Node t2.medium 3 3 eu-west-1a,eu-west-1b,eu-west-1c NODE STATUS NAME ROLE READY ip-172-20-107-234.eu-west-1.compute.internal master True ip-172-20-124-39.eu-west-1.compute.internal node True ip-172-20-44-152.eu-west-1.compute.internal master True ip-172-20-60-188.eu-west-1.compute.internal node True ip-172-20-79-79.eu-west-1.compute.internal master True ip-172-20-87-125.eu-west-1.compute.internal node True Your cluster cluster.zigzag-london.com is ready
Check out the full article at the Build Blog.
Matthew Sheppard is a Solution Architect at Slalom UK. Software engineering, cloud native architecture/infrastructure & infosec. Cannot be trusted alone with cheese. @justatad
Subscribe to The Blueprint
Want more? Subscribe now and we'll make sure you get all the latest, coolest, smartest stuff in The Blueprint.